# 案例一: from typing importAny, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun from langchain.llms.base import LLM
classCustomLLM(LLM): n: int @property def_llm_type(self) -> str: return"custom" def_call( self, prompt: str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, ) -> str: if stop isnotNone: raise ValueError("stop kwargs are not permitted.") return prompt[:self.n] @property def_identifying_params(self) -> Mapping[str, Any]: """Get the identifying parameters.""" return {"n": self.n}
llm = CustomLLM(n=10) llm("This is a foobar thing")
# 案例二: from typing importAny, List, Mapping, Optional from langchain.callbacks.manager import CallbackManagerForLLMRun from langchain.llms.base import LLM import re
classTfboyLLM(LLM):
@property def_llm_type(self) -> str: return"custom" def_call( self, prompt: str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, ) -> str: print("问题:",prompt) pattern = re.compile(r'^.*(\d+[*/+-]\d+).*$') match = pattern.search(prompt) ifmatch: result = eval(match.group(1)) elif"?"in prompt: rep_args = {"我":"你", "你":"我", "吗":"", "?":"!"} result = [(rep_args[c] if c in rep_args else c) for c inlist(prompt)] result = ''.join(result) else: result = "很抱歉,请换一种问法。比如:1+1等于几" return result
llm_chain = LLMChain(prompt=prompt, llm=local_llm) question = "What is the capital of England?" print(llm_chain.run(question))
3.2 Chain
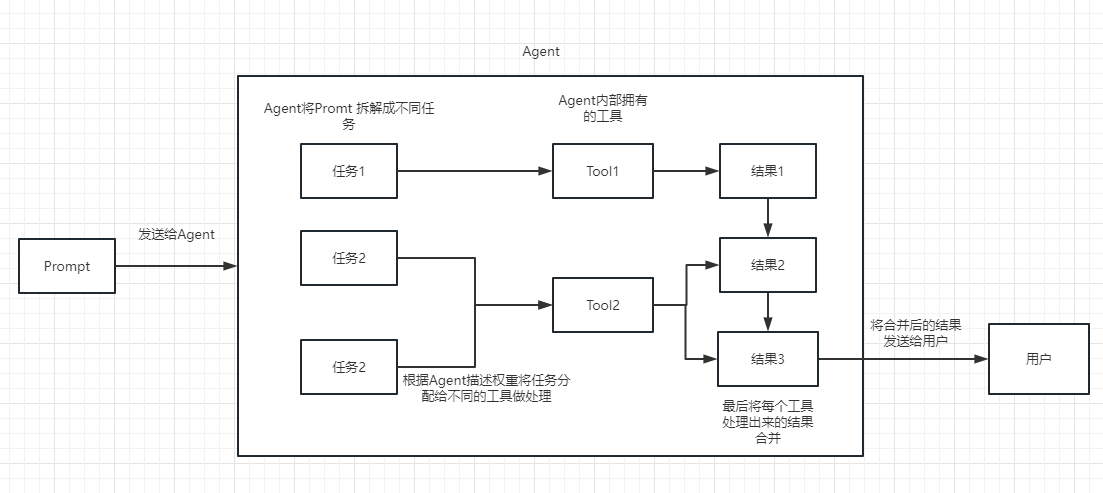
如何让应用更复杂一点?如何解决并发?chain之间如何路由?
1 2 3 4 5 6 7 8 9 10 11 12
You are given the below API Documentation:{api_docs}
Using this documentation, generate the full API url to call for answering the user question. You should build the API url in order to get a response that isas short as possible, while still getting the necessary information to answer the question. Pay attention to deliberately exclude any unnecessary pieces of data in the API call.
Question:{question} API url: {api_url}
Here is the response from the API:{api_response}
Summarize this response to answer the original question. Summary:
from langchain.chat_models import ChatOpenAI from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic from langchain.prompts import ChatPromptTemplate
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613") schema = { "properties": { "sentiment": {"type": "string", "enum": ["happy", "neutral", "sad"]}, "aggressiveness": { "type": "integer", "enum": [1, 2, 3, 4, 5], "description": "describes how aggressive the statement is, the higher the number the more aggressive", }, "language": { "type": "string", "enum": ["spanish", "english", "french", "german", "italian"], }, }, "required": ["language", "sentiment", "aggressiveness"], } chain = create_tagging_chain(schema, llm) inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!" chain.run(inp) # 输出:{'sentiment': 'happy', 'aggressiveness': 0, 'language': 'spanish'}
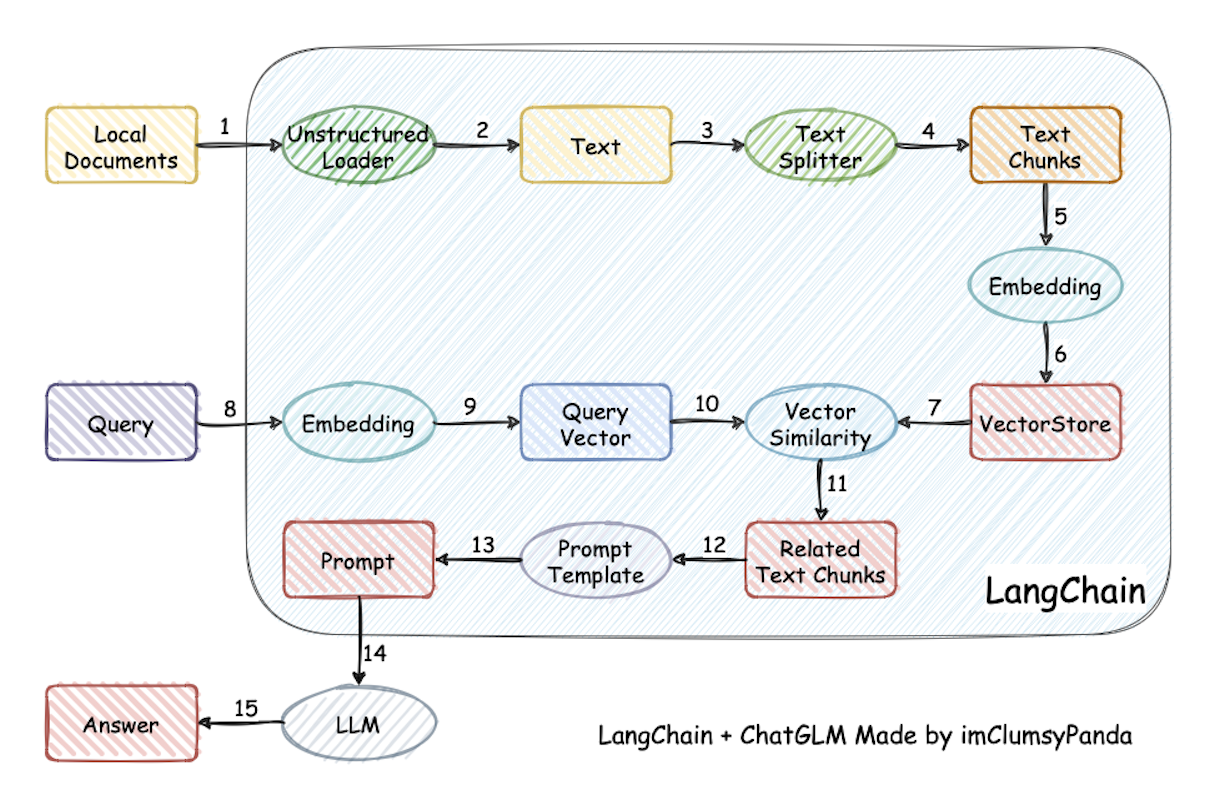
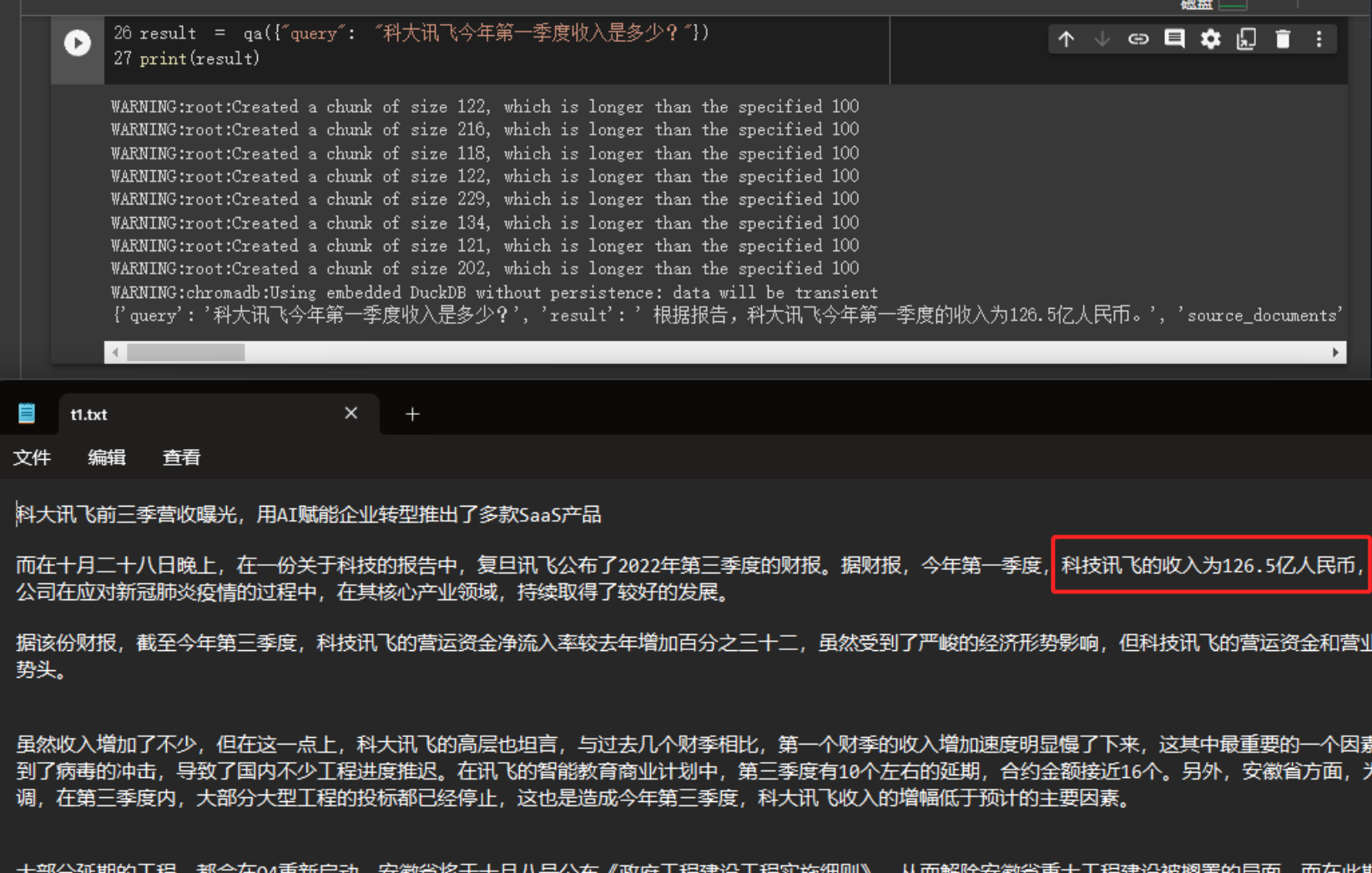
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import CharacterTextSplitter from langchain import OpenAI,VectorDBQA from langchain.document_loaders import DirectoryLoader from langchain.chains import RetrievalQA
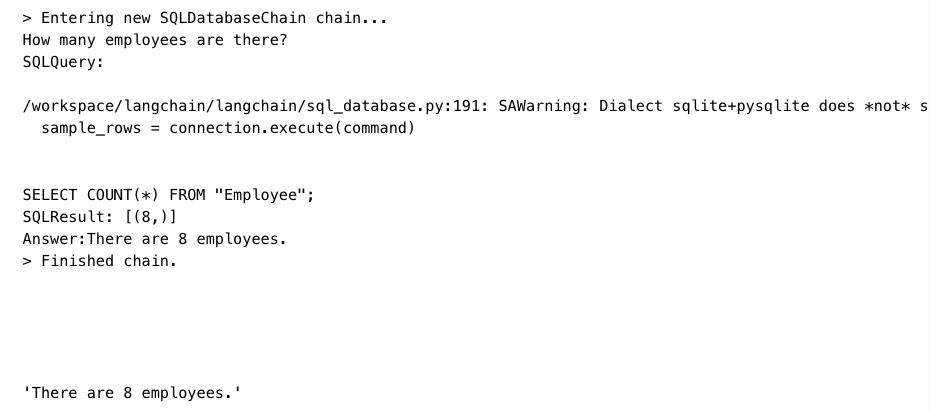
数据分析 NOTE: For data-sensitive projects, you can specify return_direct=True in the SQLDatabaseChain initialization to directly return the output of the SQL query without any additional formatting. This prevents the LLM from seeing any contents within the database. Note, however, the LLM still has access to the database scheme (i.e. dialect, table and key names) by default.
1 2 3 4 5 6
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain db = SQLDatabase.from_uri("sqlite:///../../../../notebooks/Chinook.db") llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True) db_chain.run("How many employees are there?")
3.3 Agent
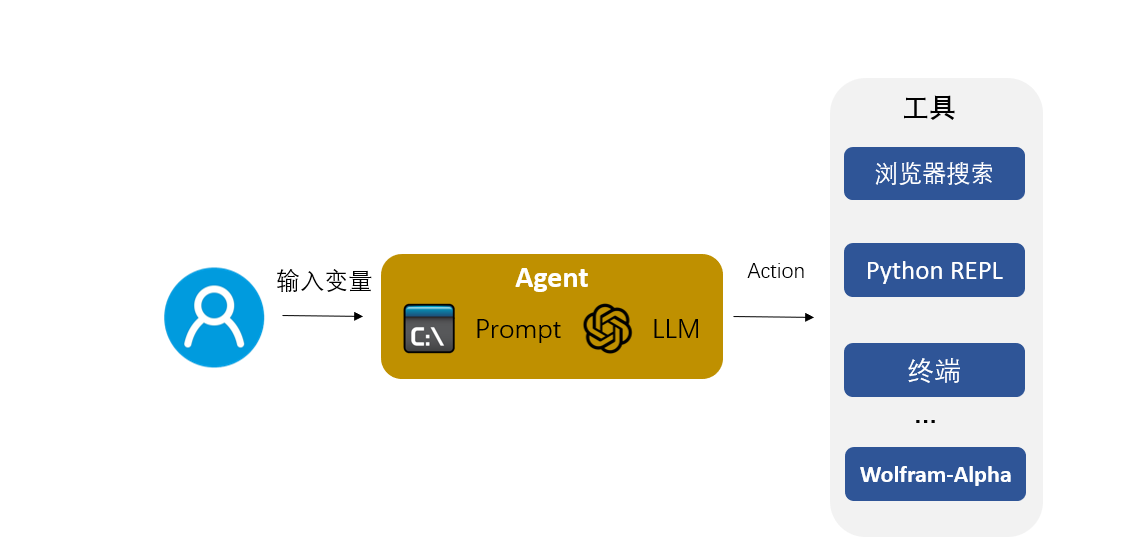
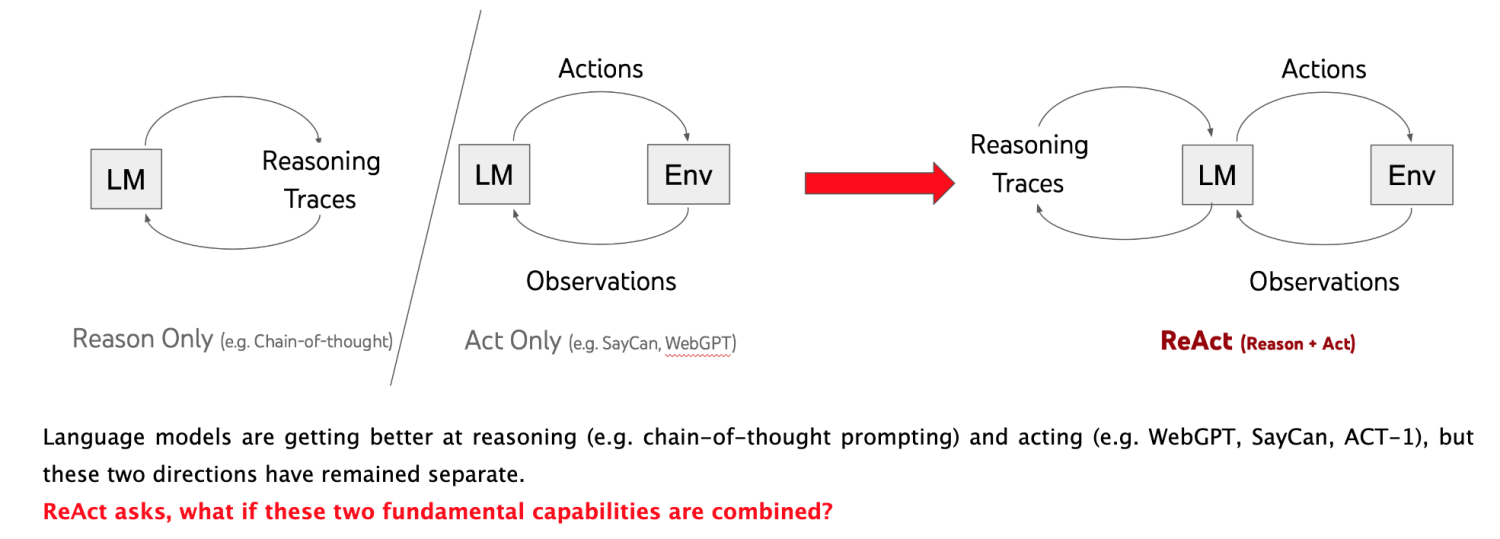
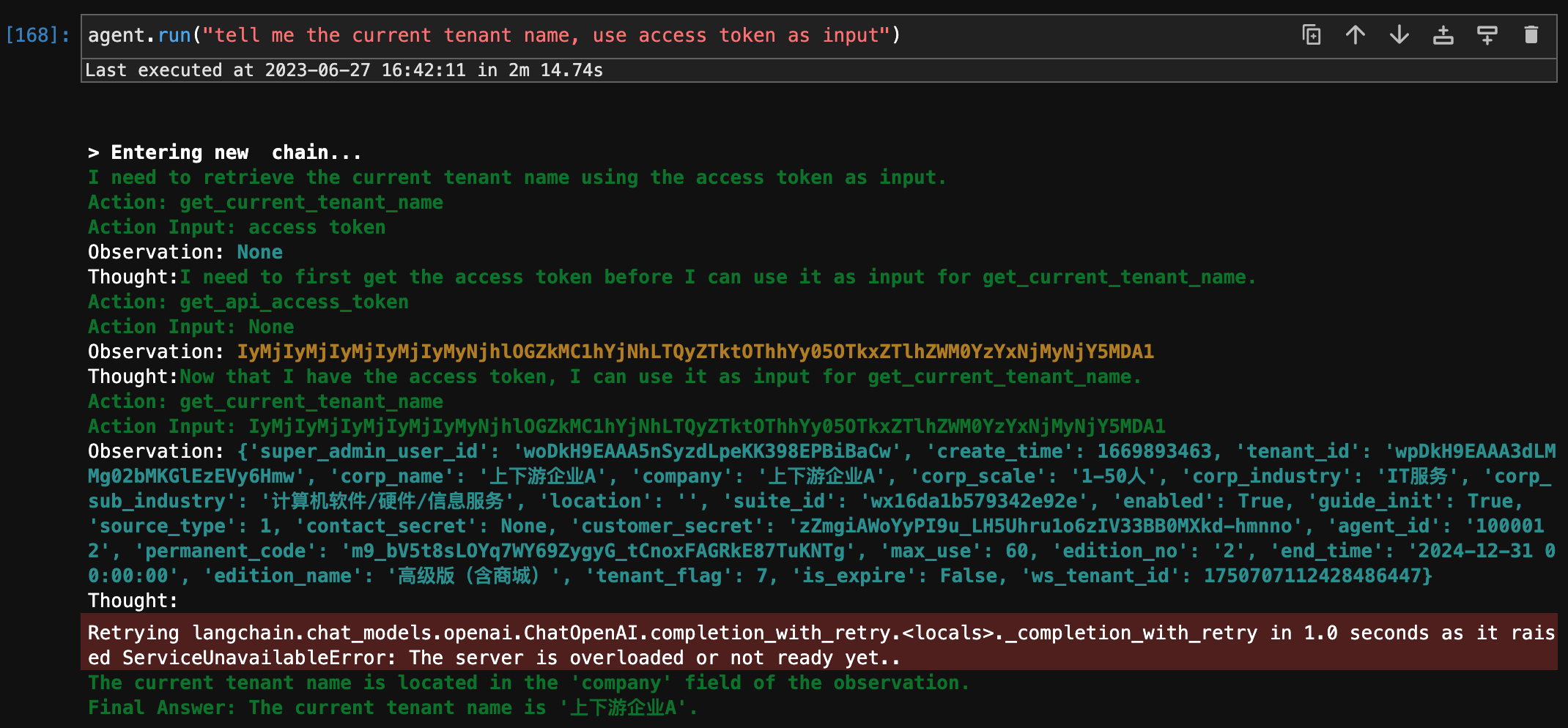
定义:The Agent interface provides the flexibility for such applications. An agent has access to a suite of tools, and determines which ones to use depending on the user input. Agents can use multiple tools, and use the output of one tool as the input to the next.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Answer the following questions as best you can. You have access to the following tools: Calculator: Useful for when you need to answer questions about math. Weather: useful for When you want to know about the weather
Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [Calculator, Weather] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: Query the weather of this week,And How old will I be in ten years? This year I am 28 Thought:
Agent的主要类别(agent_type)
Action agents: at each timestep, decide on the next action using the outputs of all previous actions
OpenAI Functions:Certain OpenAI models (like gpt-3.5-turbo-0613 and gpt-4-0613) have been explicitly fine-tuned to detect when a function should to be called and respond with the inputs that should be passed to the function. The OpenAI Functions Agent is designed to work with these models.
Plan-and-execute agents: decide on the full sequence of actions up front, then execute them all without updating the plan
3.4 Tools & Toolkits
如何自定义工具? 如何支持多输入参数?如果做参数验证?如果防止高危操作?
定义:Tools are functions that agents can use to interact with the world. These tools can be generic utilities (e.g. search), other chains, or even other agents. 自定义工具
from langchain.callbacks.manager import AsyncCallbackManagerForToolRun, CallbackManagerForToolRun
classCustomSearchTool(BaseTool): name = "custom_search" description = "useful for when you need to answer questions about current events"
def_run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None) -> str: """Use the tool.""" return search.run(query) asyncdef_arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None) -> str: """Use the tool asynchronously.""" raise NotImplementedError("custom_search does not support async") classCustomCalculatorTool(BaseTool): name = "Calculator" description = "useful for when you need to answer questions about math" args_schema: Type[BaseModel] = CalculatorInput
def_run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None) -> str: """Use the tool.""" return llm_math_chain.run(query) asyncdef_arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None) -> str: """Use the tool asynchronously.""" raise NotImplementedError("Calculator does not support async")
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
# You can provide a custom args schema to add descriptions or custom validation classSearchSchema(BaseModel): query: str = Field(description="should be a search query") engine: str = Field(description="should be a search engine") gl: str = Field(description="should be a country code") hl: str = Field(description="should be a language code")
classCustomSearchTool(BaseTool): name = "custom_search" description = "useful for when you need to answer questions about current events" args_schema: Type[SearchSchema] = SearchSchema
from langchain.chat_models import ChatOpenAI from langchain.agents import load_tools, initialize_agent from langchain.agents import AgentType from langchain.tools import AIPluginTool
agent_chain = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) agent_chain.run("what t shirts are available in klarna?")
import os os.environ["ZAPIER_NLA_API_KEY"] = '' from langchain.llms import OpenAI from langchain.agents import initialize_agent from langchain.agents.agent_toolkits import ZapierToolkit from langchain.utilities.zapier import ZapierNLAWrapper