一.压测工具介绍
工欲善其事必先利其器
(1)Jmeter介绍
**下载地址 **https://jmeter.apache.org/download_jmeter.cgi
操作文档:https://www.cnblogs.com/185RSF/articles/16895202.html
(2)Arthas - 阿尔萨斯
官方文档:https://arthas.aliyun.com/doc/download.html
Jetbrains 插件获取地址: https://plugins.jetbrains.com/plugin/13581-arthas-idea
二.影响接口QPS的点有哪些
(一) tomcat线程数的配置
(1)accept-count:最大等待数
当所有的请求处理线程都在使用时,所能接收的连接请求的队列的最大长度。当队列已满时,任何的连接请求都将被拒绝。accept-count的默认值为100。
详细的来说:当调用HTTP请求数达到tomcat的最大线程数时,还有新的HTTP请求到来,这时tomcat会将该请求放在等待队列中,这个acceptCount就是指能够接受的最大等待数,默认100。如果等待队列也被放满了,这个时候再来新的请求就会被tomcat拒绝(connection refused)。
(2)maxThreads:最大线程数
每一次HTTP请求到达Web服务,tomcat都会创建一个线程来处理该请求,那么最大线程数决定了Web服务容器可以同时处理多少个请求。maxThreads默认200,肯定建议增加。但是,增加线程是有成本的,更多的线程,不仅仅会带来更多的线程上下文切换成本,而且意味着带来更多的内存消耗。JVM中默认情况下在创建新线程时会分配大小为1M的线程栈,所以,更多的线程异味着需要更多的内存。线程数的经验值为:1核2g内存为200,线程数经验值200;4核8g内存,线程数经验值800。
(3)maxConnections:最大连接数
这个参数是指在同一时间,tomcat能够接受的最大连接数。maxConnections和accept-count的关系为:当连接数达到最大值maxConnections后,系统会继续接收连接,但不会超过acceptCount的值。
** (4) maxConnections、maxThreads、acceptCount关系图**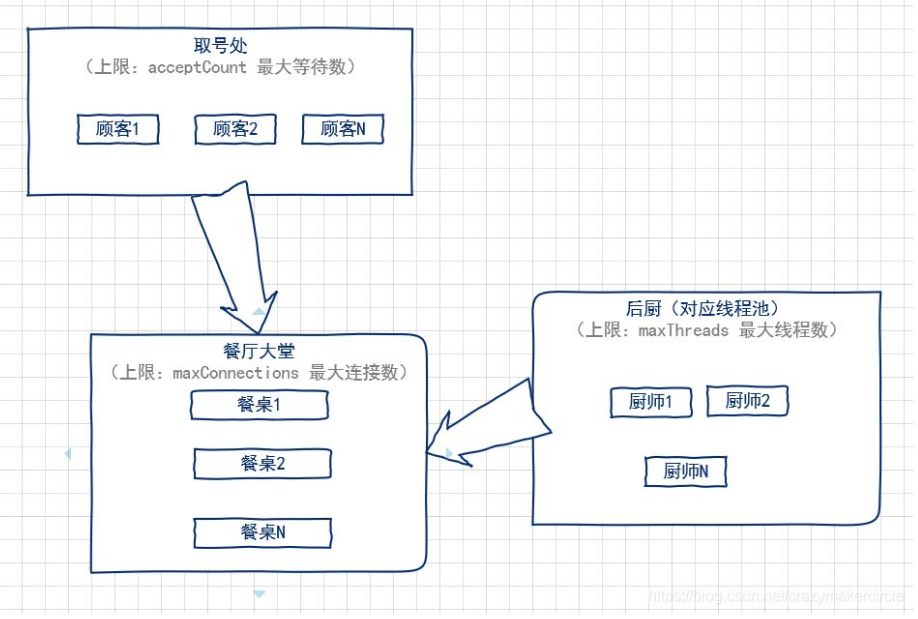
(5)代码用例压测演示

结论:qps = acceptCount + maxConnections
(二) CPU的利用率
当cpu是利用率飙升的时候,说明代码中有特别消耗cpu的方法
- 死循环、递归消耗CPU。
- 正则消耗CPU。
- 线程数线程数增多,通常会伴随内存飙升,但是线程内本身无复杂业务,会呈现,只有CPU飙升,但内存增高不明显。
- 死锁死锁会导致核心线程数无响应,间接导致线程数飙升。
(1)代码用例压测演示
当方法中不耗cpu时
当方法中有递归或者循环时,耗cpu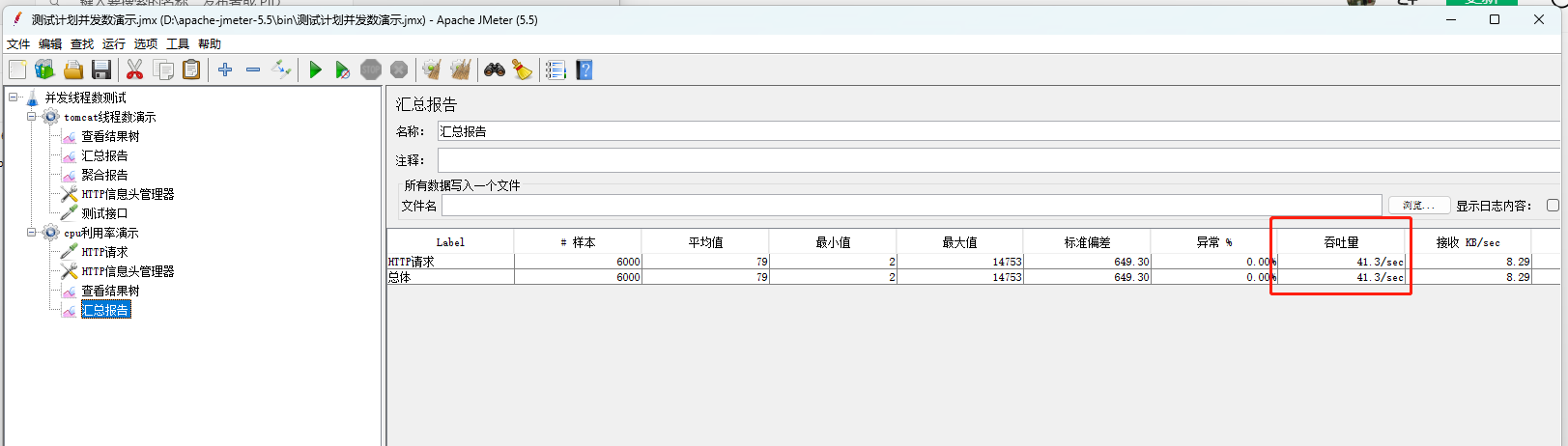
(三) 内存使用率
当内存过高时会导致java虚拟机频繁的GC,QPS也会明显下降
(四) 接口的响应时间
当接口的响应时间越快,QPS就会越高
三.抽奖详情的优化
(一) 接口业务逻辑梳理
| 1.校验参数和获取登录信息 |  |
该模块耗时可以忽略,不需要优化 |
|---|---|---|
| 2.获取抽奖活动信息 |  |
该模块需要查数据库,每次固定耗时30ms,需要优化成读缓存 |
| 3.获取客户的externalUserId |  |
该模块平均耗时150ms左右,需要重点优化 |
| 4.获取客户额外的答题抽奖次数 |  |
该模块需要转三方externalUserId转自建明文externalUserId |
| 5.构建前端返回值 |  |
该模块有3次数据库查询操作,一次feign接口调用操作,需要重点优化 |
| 6.保存访问记录 |  |
该模块有个落库的操作,固定耗时20ms,可以异步处理 |
| 7.拼接中奖记录,剩余次数,抽奖记录 |  |
该模块有3次数据库查询操作,固定耗时100ms左右,需要优化 |
(二) 各模块优化方案
(1)获取抽奖活动信息
该模块可以通过缓存获取,第一次查数据库,后续查缓存,缓存30s。优化后该模块耗时可以缩短到5ms以内
**(2)获取客户的externalUserId **
进入抽奖接口不用获取externalUserId,可以在进入小程序的时候通过其它接口返回给前端,然后前端将externalUserId传入到进入抽奖的接口中,具体流程如下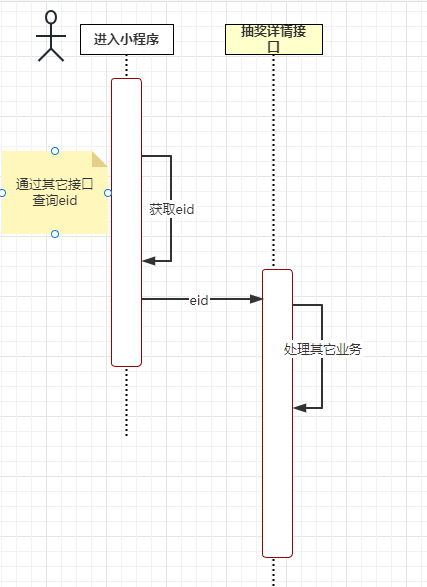
**(3) 拼接中奖记录,剩余次数,抽奖记录 **
a.前端异步加载方式,进入抽奖详情的时候,后端返回给前端该客户是否为第一次抽奖标识,根据这个标识再调一个接口返回该客户的剩余次数,抽奖记录,中奖记录
b.后端通过缓存的方式来确认是否要返回给前端客户的剩余次数,抽奖记录,中奖记录;如客户在抽奖完成后,向缓存中塞一个已参与的记录,进入抽奖详情的时候,通过这个缓存的值来判断是否需要返回剩余次数,抽奖记录,中奖记录
c.在返回客户的剩余次数,抽奖记录,中奖记录前,查询下数据库,如果数据库存在抽奖记录,则返回,不存在,则不返回
这样耗时可以缩减到30ms
(三) 调用链路耗时分析
(1)Arthas接口分析演示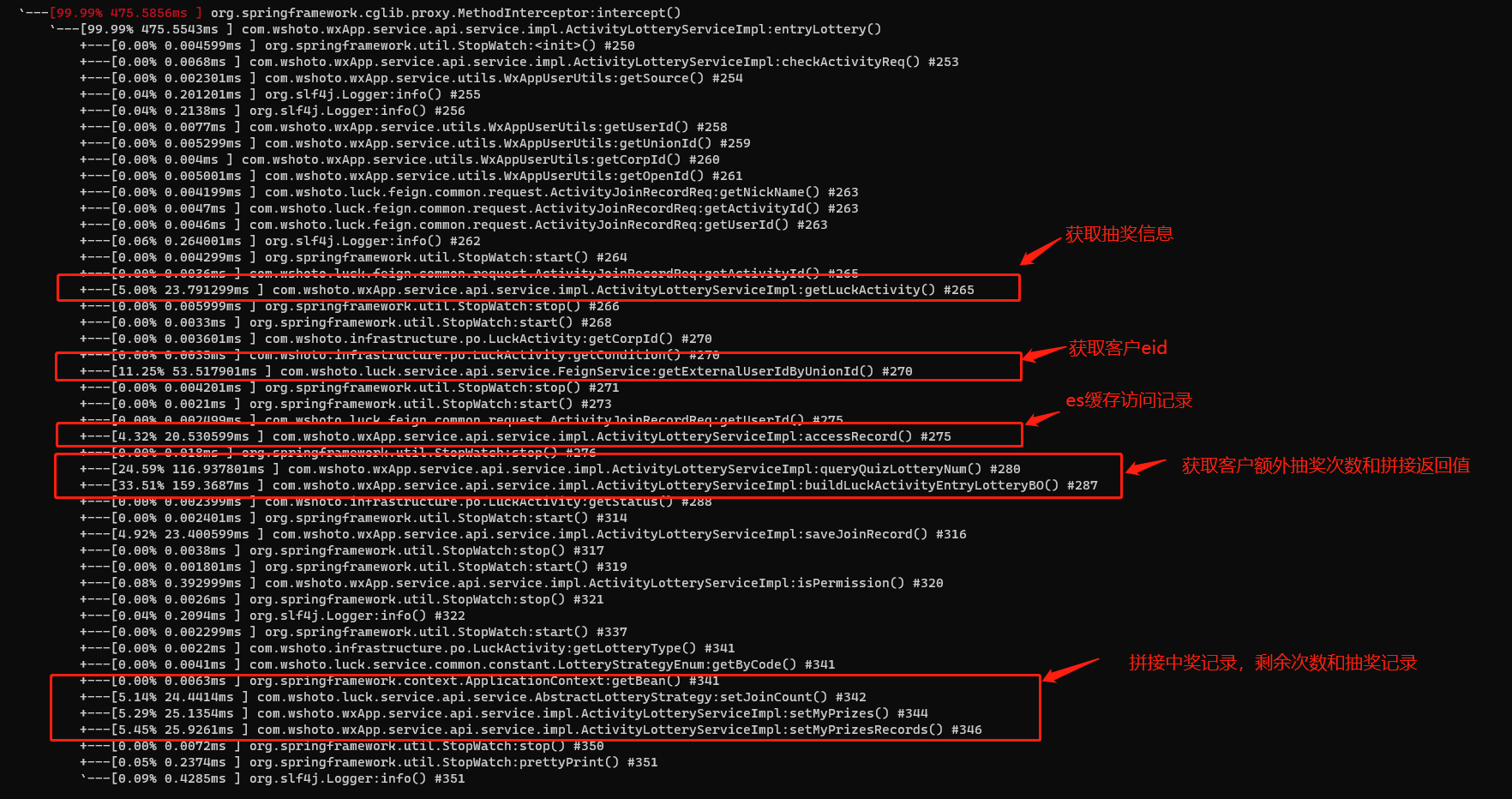
1.获取抽奖信息的时候,因为抽奖信息是很少有变动的情况,所以设置个15s左右的缓存可以有效的减少和数据库的交互,直接从内存里拿数据;
2.获取客户id信息,这个业务是需要查询外部feign接口的,所以这个地方改成了进入抽奖页面的时候,通过获取用户信息的接口,把客户id返回给前端。然后前端调这个接口的时候,把客户id带给后端,这样就能有效的增加进入抽奖的QPS;
3.保存客户的访问记录,该业务不是必须实时性的业务,可以通过异步化的方式来处理,减少了主流程中保存访问记录的操作;
4.拼接抽奖返回记录的时候,减少前端不需要的字段,减少网络层面的开销
三.总结
优化代码,能用缓存的地方尽量用缓存来处理,合理的缓存是很有效的解决耗时问题
减少feign接口的调用
加服务器资源
作者: 阿杜